Mikrosimulering
Overordnet styres fremskrivningen i SMILE af estimerede adfærdsmønstre, der via Monte Carlo simulationer, bestemmer adfærden for modellens agenter, dvs. individer og familier. Det tilstræbes at udvælgelsen af algoritmer til at estimere overgangssandsynligheder primært er datadrevet ved at benytte krydsvalidering. Dog er modeludviklingen også til dels præget af den erfaring, der besiddes af modeludviklere i DREAMgruppen. Den erfaringsdrevne modeludvikling beror sig primært på udvælgelse af relevant data, valg af estimationsperiode og udvælgelse af relevante algoritmer til at beregne overgangssandsynligheder.
Andre vigtige metoder i mikrosimulering er alignment, dvs. tilpasning af modellen til udviklingen i eksempelvis befolkningen og arbejdsstyrken fra andre fremskrivninger og matching, der binder enkeltpersoner sammen i familier.
Hændelser i SMILE
SMILE består af en række moduler, som årligt sørger for at udsætte modellens agenter, dvs. individer og familier, for de hændelser, der vil give anledning til et skifte i agentens beskrivende baggrundskarakteristika, såfremt de indtræffer. Her gives et overblik over modellens moduler og de hændelser, der er knyttet hertil.
En familie kan eksempelvis bestå af en mand på 32 år og en kvinde på 29 år, som har henholdsvis en erhvervsfaglig uddannelse og en kort videregående uddannelse og sammen har et barn på 2 år. Som nævnt indledningsvist kan en given hændelse enten vedrøre alle personer i familien eller blot det enkelte individ. Hændelser som flytning, valg af tilflytningskommune og valg af bolig er typisk knyttet til hele husstanden, hvilket er med til at sikre, at de rigtige personer bliver sammen i en familie i kraft af fælles flytte- og boligvalg. Familier kan omvendt nedbrydes til nye familier, hvis børn flytter hjemmefra eller hvis to voksne opløser deres samliv. Beslutninger vedrørende uddannelse og arbejdsmarkedstilknytning finder i modellens nuværende form sted på individniveau, men kan i kraft af kendskabet til personernes indbyrdes forhold teoretisk set betinges af en eventuelt partners forudgående valg.
SMILE består af følgende overordnede moduler:
- Demografi
- Flytning og boligvalg
- Socioøkonomi (uddannelse og arbejdsmarked)
- Indkomst og pension
- I samtlige moduler findes hændelser målrettet modellens individer, mens hændelser på familieniveau næsten entydigt findes i modulet beskrivende flytning og boligvalg.
Forenklet kan hændelsesstrukturen i løbet af et fremskrivningsår i SMILE skitseres som angivet i figuren nedenfor. Her fremgår det også, hvilke hændelser, der er knyttet til de enkelte moduler.
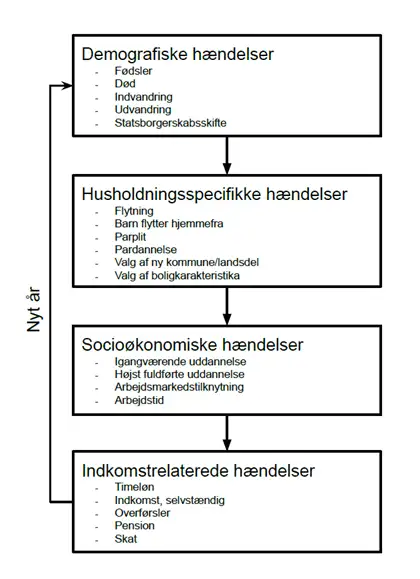
I starten af hvert fremskrivningsår bestemmes en række demografiske hændelser såsom død, fødsel og udvandring. Indvandring bestemmes dog først i slutningen af året og afviger derfor i praksis for ovenstående figur. Herefter bestemmes en række flytte– og boligvalg, som relaterer sig til flytninger indenfor landets grænser. Når alle familier er placeret i en bolig, bestemmes de socioøkonomiske hændelser i det nye år. Først fastlægges om en person starter på en uddannelse eller om man fortsætter eller færdiggør et igangværende uddannelsesforløb. Herefter fastlægges personens arbejdsmarkedstilknytning og arbejdstid. Når socioøkonomiske hændelser er fastlagt, bestemmes indkomstrelaterede hændelser såsom erhvervsindkomst, indkomsterstattende overførsler, pensionsind- og -udbetaling og beskatning. Rækkefølgen som hændelserne antages at indtræffe i, har generelt stor betydning for udfaldet.
Selvom hændelser vedrørende flytning og boligvalg er hierarkisk placeret ovenover socioøkonomiske hændelser, så kan socioøkonomiske karakteristika godt påvirke flyttehændelserne – der vil blot være tale om socioøkonomisk status fra det foregående kalenderår. Eksempelvis afhænger de fleste flyttesandsynligheder af arbejdsmarkedstilknytning og uddannelsesniveau ved årets start. Hvis man ønsker, at en ændring i socioøkonomisk status skal påvirke flyttemønsteret allerede i samme år, skal hændelsesrækkefølgen ændres og sandsynlighederne reestimeres, så disse ikke længere afhænger af socioøkonomi i starten af året, men i stedet i slutningen af året.
For nogle personer, er der hændelser, som slet ikke er relevante. Eksempelvis er det ikke relevant, at fastlægge om personer udenfor den fertile alder får et nyfødt barn. På samme vis er det ikke relevant at udsætte en person, der allerede lever i et par for muligheden for at indgå i pardannelse. For at optimere afviklingen af modellen, eksekveres hændelser kun for de individer eller familier, hvor de er relevante.
Hvor stor er SMILE?
I gruppebaserede modeller kan antallet af grupper og dermed størrelsen af modellen dog hurtigt øges betydeligt. Med 120 aldre, to køn, fem oprindelsesgrupper, seks uddannelsesgrupper, ni arbejdsmarkedsgrupper og 98 kommuner har en sådan model 120 ∙ 2 ∙ 5 ∙ 6 ∙ 9 ∙ 98 = 6.350.400 grupper. Mens en gruppebaseret model således hurtigt kan eksplodere størrelsesmæssigt, ligger antallet af individer i en mikrosimulationsmodel nogenlunde fast. For den danske befolkning fremskrives omkring 5.6 mio. individer og befolkningstallet ændres kun med få procent hvert år uanset, hvor mange karakteristika, de enkelte individer beskrives med. Dette imødekommer en række af de udfordringer, som i gruppebaserede modeller begrænser detaljeringgraden og udviklingspotentialet, jf. Hansen m.fl. (2013).
Som nævnt ovenfor, så kan de overgangssandsynligheder, der er knyttet til de enkelte hændelser i SMILE, nuanceres på stort set alle de personspecifikke karakteristika, der findes i modellen. Dette giver i udgangspunktet anledning til et curse-of-dimensionality problem, når overgangssandsynlighederne skal estimeres. Dette betyder, at data er meget tyndt for visse kombinationer af karakteristika. Eksempelvis haves ikke på nuværende tidspunkt særligt mange efterkommere i befolkningen med en lang videregående uddannelse og det er derfor vanskeligt at estimere en overgangssandsynlighed for denne gruppe. I SMILE løses denne udfordring dog ved anvendelse af en række estimationsteknikker, der reducerer dimensionaliteten i adfærdsmønsteret ved at sammenlægge grupper, der vurderes at være statistisk ens mht. en given hændelse.
Dette kan illustreres ved fastlæggelse af boligens anvendelse (dvs. parcelhus, rækkehus, etagebolig etc.), når familierne udsættes for boligvalgshændelsen i forbindelse med flytning. Der er i alt 8 typer af anvendelse, og der er potentielt 34*1018 (trillioner eller million million milliarder) mulige sandsynligheder givet de forklarende variable, der omfatter:
- de voksnes gennemsnitsalder,
- fra- og tilflytningskommuner,
- uddannelsesniveau for begge voksne,
- herkomst for begge voksne,
- arbejdsmarkedstilkytning for begge voksne,
- børn i familien eller ej.
Ved således at anvende en varians-reducerende estimationsmetode kaldet CTREE, reduceres antallet af estimerede sandsynligheder til 4.393. Det vurderes med andre ord, at sandsynligheden for at vælge en bestemt anvendelsestype kun antager 4.393 forskellige værdier og der dermed er en lang række af persongrupper, der dermed har den samme sandsynlighed.
SMILEs byggeklodser
De vigtigste grundsten i konstruktionen af SMILE er:
- registerdata,
- estimation af overgangssandsynligheder,
- estimation af imputationsmodeller,
- alignment (tilpasning til andre makrotal)
- og matching af personer, som danner par i modellen.
Første trin i konstruktionen af SMILE er at sammensætte registerdata, som skal bruges til to primære formål. For det første skal der laves en startpopulation, hvor hvert individ karakteriseres ved en lang række karakteristika så som alder, køn, boligforhold, arbejdsmarkedstilknytning, indkomstforhold mv.
For det andet skal der estimeres overgangssandsynligheder, som bestemmer udfaldene af de hændelser, agenterne i modellen udsættes for. DREAM har adgang til registerdata gennem Danmark Statistiks forskerordning og underligger strenge krav til behandling af data.
Danmark har et af verdens mest omfattende registre med oplysninger om landets borgere. Registret omfatter en lang række områder, men har dog på nogle områder sine begrænsninger, så der er nogle oplysninger, der ikke er tilgængelige for alle borgere. For at alle individer i SMILE har de nødvendige oplysninger for det, som ønskes simuleret, kan det være nødvendigt at anvende en imputationsmodel. Hvis årslønnen for en person eksempelvis er ukendt, kan man med en imputationsmodel tildele en årsløn, som ligner den personer med tilsvarende alder, køn og uddannelse eksempelvis har. Imputationsmodeller bruges også til at tildele ukendte værdier til nye indvandrere, der hvert år sættes ind i modellen.
Endeligt benyttes registerdata til at beregne overgangssandsynligheder.
Nogle overgangssandsynligheder i SMILE alignes. Ved alignment afstemmes de estimerede sandsynligheder, så modellens fremskrivning i højere grad tilpasses særlige scenarier fremadrettet. Det kan eksempelvis være, hvis det ønskes at modellen tilpasses dødeligheden i den nationale befolkningsfremskrivning eller uddannelsesadfærden i en anden uddannelsesfremskrivning. I basisfremskrivningen i SMILE alignes der eksempelvis til antallet af døde og fødte i den nationale befolkningsfremskrivning.
Endelig anvendes en matching-algoritme, som sammensætter personer i par. Matching algoritmen er designet så den skaber par med karakteristika som eksempelvis alder og uddannelse der ligner de par som man observerer i familierne.
Mere om SMILES byggeklodser
Idenfor kan læses en mere uddybende beskrivelse af SMILEs byggeklodser.
Imputation
En fremskrivning i SMILE baseres på en startbefolkning fra et historisk år. I de tilfælde, hvor der mangler værdier for data i startåret, bruges imputation til at danne sandsynlige værdier.
Hændelser i SMILE er primært bestemt af estimerede overgangssandsynligheder, der typisk afhænger af, hvilke karakteristika en agent har året før. Derfor er det nødvendigt at beskrive startbefolkningen med alle variable, der indgår i bestemmelsen af modellens overgangssandsynligheder. I de tilfælde, hvor der mangler værdier for data i startåret bruges imputation.
Der er generelt tre årsager til, at værdier for data må imputeres:
- Værdien er ikke tilgængelig for alle personer i registerdata.
- Værdien kommer fra et survey, der ikke dækker hele befolkningen og sandsynligvis heller ikke er lavet i samme år, som SMILEs simulering starter i.
- Nogle værdier er af juridiske årsager ikke mulige at opnå tilgang til på serveren, hvor SMILE befinder sig.
Ved imputering indsættes en kunstig værdi, som gerne skal en rimelig repræsentation, af hvad værdien rent faktisk kunne have været. Dette kan gøres ved brug af relative simple metoder. Eksempelvis kunne man vælge gennemsnitsværdien eller medianen af timelønnen og indsætte denne for alle personer, der mangler en timeløn. En sådan simpel tilgang vil typisk ikke være særlig præcis. Derfor vil det ofte være hensigtsmæssigt at bruge mere avancerede algoritmer. For timeløn kan det være oplagt at bruge en regressionsmodel samt et tilfældigt trukket fejlled, mens en manglende uddannelsesoplysning kan imputeres ved en klassifikationsmodel. Det er også en mulighed at trække en tilfældig værdi fra en historisk fordeling. En sidste mulighed kan være at sætte manglende værdier til en default værdi. Eksempelvis sættes en manglende værdi for højst fuldførte uddannelse i praksis til ”Grundskole” i SMILEs startår. For estimerede imputationsmodeller anvendes samme procedure som ved estimation af overgangssandsynligheder.
Overgangssandsynligheder
Beregningen af sandsynligheder i SMILE er afgørende for, hvilke hændelser der indtræffer for agenterne i modellen. Fagligt betegnes disse sandsynligheder som overgangssandsynligheder, fordi de bestemmer sandsynligheden for at overgå fra en tilstand til en anden.
Metodevalget til at beregne overgangssandsynligheder er på den ene side datadrevet, men afhænger også af en række antagelser.
Valget af model til at beregne overgangssandsynligheder er drevet af data, fordi metoden til at beregne overgangssandsynligheder bestemmes af, hvilken model, der prædikterer bedst på nyt data. Prædiktionsevne bestemmes på baggrund af krydsvalidering af et relevant performance mål for modellen.
Krydsvalidering
For at kunne vurdere forskellige modellers prædiktionsevne (og der ved fastlægge overgangssandsynligheder) bruges krydsvalidering. Det sker ved i praksis at data deles op i et trænings-sæt og et test-sæt.
Træningssættet deles herefter yderligere op i 10 sæt (se figur). Ud fra disse 10 datasæt laves 10 resamples. Hver resample opdeles i hhv. et analyse-datasæt og et vurderingssæt. Hver analysesæt indeholder 9 af de opdelte træningssæt, mens vurderingssættet udgøres af det resterende sæt data. Det giver mulighed for at estimere/træne en given model 10 gange, hvor modellen både trænes og evalueres med forskellige sammensætninger af data.
Denne krydsvalideringsproces kaldes k-fold cross-validation og er i SMILE den dominerende metode, fordi estimationerne er baseret på store datasæt. Der findes også andre mere avancerede krydsvalideringsmetoder, som dog i højere grad er rettet mod mindre datasæt, hvor præcisionen af estimationerne kan være et problem.
Se Kuhn og Johnson (2019)1 for en videre diskussion af krydsvalideringsmetoder.
Modeludvælgelse
Modeller, som bestemmer overgangssandsynligheder for hændelser i SMILE, vælges på baggrund af, hvor godt modellerne performer ved krydsvalidering. Et eksempel kan være, at man bruger en logistisk regression til at estimere sandsynligheden for, at en person dør. I en type model (model 1) bestemmes sandsynligheden for at dø kun ud fra alder, mens en anden model (model 2) både inkluderer alder og køn. Hvis model 2 klarer sig bedre en model 1, vælges model 2 og omvendt.
Der bruges andre typer algoritmer end logistisk regression til at lave en prædiktionsmodel. Den dominerende algoritme, der bruges i SMILE er det såkaldte CTREE (Conditional Inference Tree). Ovenstående eksempel kunne således udvides med, at man har en tilsvarende model 3 og model 4, der på samme måde estimere sandsynligheden for at dø på baggrund af hhv. alder eller alder og køn. Den optimale model af 3 og 4 udvælges. Herefter undersøges performance af forskellige modeltyper på test data. I nedenstående figur er processen stillet skematisk op. Her vises proceduren for en række udvalgte algoritmer, som kunne anvendes til et klassifikationsproblem.

Selvom det tilstræbes, at modelvalget primært er datadrevet, så er modeludviklingen også til dels præget af den erfaring, der besiddes af modeludviklere i DREAM. Den erfaringsdrevne modeludvikling beror sig primært på udvælgelse af relevant data, valg af estimationsperiode og udvælgelse af relevante algoritmer til at beregne overgangssandsynligheder.
Typisk kan mere komplekse modeller som Random Forest give bedre prædiktion, men mere udfordrende at implementere i praksis. Der er eksempelvis ikke for nuværende en implementering af Random Forest i SMILE, men modellen kan bruges som performance-benchmark af øvrige (og mere simple) modeller, som lettere kan implementeres i SMILE. Særligt hvis mere simple modeller performer nogenlunde ligeså godt som mere komplekse modeller, kan de simple modeller være fordelagtige, fordi de ofte er nemmere at tolke på og nemmere at implementere. Se kapitel 4 i Applied Predictive Modeling (Kuhn og Johnson , 2013)1 for en videre diskussion af udvælgelse af modeltyper.
Performancemål
Det er vigtigt at evaluere sine modeller på baggrund af relevante performancemål. Valget af performance mål for estimationsmodellerne afhænger i første omgang af, om der skal prædikteres en numerisk værdi, så der er tale om en regressionsmodel, eller om der skal prædikteres en kategori, så der er tale om en klassifikationsmodel.
Det er ofte simplere at vælge performancemål for regressionsmodeller, fordi der overordnet er to dominerende mål. Det første mål er modellens gennemsnitlige afvigelse (Mean Average Error/MAE), men det andet og mest populære er mål er den gennemsnitlige kvadrerede afgivelser (Root mean squared error/RMSE). I begge tilfælde performer en model bedre, jo lavere MAE eller RMSE den har. Her foretrækkes RMSE ofte, fordi målet i højere grad ”straffer” modeller, hvor der er punkter med høj afvigelse. I andre tilfælde kan MAE være at foretrække, hvis der ønskes en model, der er mindre sensitiv overfor ”outliers”.
For klassifikationsmodeller er der en lang række muligheder for at måle en models performance. For nogle klassifikationsproblemer er den primære interesse at lave ”hårde” prædiktioner (f.eks. har en person en livstruende sygdom eller ej), mens det for andre klassifikationsproblemer er mere relevant af lave ”bløde” prædiktioner, hvor det er klasse-sandsynlighederne, der har den primære interesse (f.eks. hvad er sandsynligheden for, en person har en livstruende sygdom). Man kan sige, at der kan sondres i mellem om modellen skal identificere de korrekte personer eller blot skal identificere et korrekt gennemsnit.
Til fremskrivningen i SMILE anvendes en kombination of estimerede sandsynligheder og Monte Carlo simulation.
Derfor er den primære interesse i SMILE, at lave modeller, der er optimeret i forhold til at prædiktere klasse-sandsynligheder fremfor egentlig klasser, som først endeligt afgøres ved Monte Carlo simulation. Her er det en fordel, at bruge log-likelihood2 både for klassifikationsproblemer med to udfald men også for tre eller flere udfald, fremfor performance mål som accuracy, precision, sensitivity, specificity eller AUC, som i højere grad relaterer sig til ”hårde” prædiktioner3. Den bedste model udvælges ved at vælge den model, hvor log-likelihood maksimeres. Log likelihood maksimeres ved at værdier blandt observationer prædikteres til den rigtige klasse med høj sandsynlighed. I forhold til andre performance mål, giver log-likelihood tilgangen mulighed for at tage med i vurderingen, hvor meget den prædikterede sandsynlighed afviger fra den faktiske prædiktion.
Visualisering af resultater
Det kan være fornuftigt at visualisere resultatet af sine estimationer for at vurdere, om der er oplagte mønstre i data, som modellen ikke fange, selvom en prædiktiv models performance formelt vurderes på baggrund af statistiske performance mål.
Ved klassifikationsmodeller prædikteres klassesandsynligheden for alle observationer. Herefter laves en klassificering ved hjælp af Monte Carlo simulation. Det giver mulighed for, at eksempelvis andelen af prædikterede døde fordelt på alder kan holdes op mod den faktiske andel, der dør, opdelt på alder. Et eksempel er vidst nedenfor, hvor antallet og andelen af døde er vist for test-data (altså data som ikke er blevet anvendt i estimationen) og den simulerede andel/antal af døde på baggrund af karakteristika i test data. Dette giver en uformel inspektion af modellens performance på out-of-sample prædiktion, som kan anvendes til at vurdere modellens præcision i sammenhold med modellens performance mål.
Visualisering kan også give indblik i modellens performance, når der opsplittes på flere karakteristika. Nedenfor er antallet af døde simuleret ved Monte Carlo simulation anvendt på de estimerede sandsynligheder sammenholdt med det faktiske antal døde opdelt på alder, køn og parstatus. Eksemplet her er baseret på et 50 pct. sample af den samlede population i årene 2010-2012. Træningsdata udgør 80 pct. af samplet (ca. 6.656.000 observationer) og test data udgør 20 pct. af sample (ca. 1.664.000 observationer). Dødssandsynligheder er estimeret på et CTREE, der er blevet tunet ved 10-folds krydsvalidering.
Det faktiske antal døde og det simulerede antal døde opdelt på alder, parstatus og køn, viser i tilfældet her, at modellen umiddelbart virker til at ramme mønstre i data meget fornuftigt.

På samme vis giver en visualisering af den faktiske og den simulerede andel af døde opdelt på alder, parstatus og køn indtryk af, at modellen prædikterer en fornuftig fordeling af andelen af døde på tværs af de viste karakteristika.

Matching
I SMILE anvendes matchning til pardannelse. Algoritmen baseres på historiske pardannelsesmønstre.
Matching bruges til dannelse af par i SMILE. Proceduren foregår i to trin. I første trin laves en pulje af enlige, som indgår i en matchingpulje. I andet trin bruges en matching-algoritme, som sammensætter de enlige i par.
Dannelse af matching-puljen bestemmes ved at enlige udsættes for en matching hændelse, der afgøres som ved Monte Carlo simulation i kombination med estimerede overgangssandsynligheder. Herefter sammensætter en matching-algoritme enlige i par på baggrund af historiske mønstre for pardannelse. For eksempel ses det typisk, at mænd danner par med kvinder, at mænd er et par år ældre end deres partner og den nye partner typisk bor i samme geografiske område. Når enlige i matchingpuljen parres, sørger matching-algoritmen for, at den historiske fordeling af enlige, som danner par, i størst mulig omfang fastholdes. Konkret anvendes metoden Sparse Bipropriate Adjustment Matching (SBAM), hvor en teknisk fremstilling kan læses i Stephensen (2012).
Alignment
I mikrosimuleringsmodeller anvendes ofte alignment, som hjælper til styrer modellen i retning af nogle ønskede makrotal. Dette gør sig også gældende i SMILE.
I SMILEs basisfremskrivning alignes der eksempelvis til fødsler, dødsfald og udvandring, så den samlede udvikling i disse komponenter er sammenfaldende med de tilsvarende bevægelser i befolkningsfremskrivningen, som DREAM laver i samarbejde med Danmark Statistik. Denne tilpasning foregår i praksis ved at justere i overgangssandsynlighederne i SMILE.
I SMILE bruges der metoden Logit Scaling4, som er udviklet i DREAM.
Monte Carlo simulation
I SMILE bestemmes den egentlige klassifikation af Monte Carlo-simulation i kombination med de estimerede sandsynligheder. Det vil sige, at der trækkes et tilfældigt tal mellem 0 og 1 for hver observation. Givet den tilfældige værdi er mindre end klassesandsynligheden, tildeles den givne klasse.
I figuren nedenfor illustreres mekanismen for en situation for to klasser og en for flere klasser. I eksemplet med to klasser er estimeret en sandsynlighed på 30 pct. for, at en person højest har en grundskole uddannelse, mens sandsynligheder for personen har en højere uddannelse er 70 pct. Her trækkes et tilfældigt tal til 0.18 og agentens uddannelsesniveau klassificeres derfor som ”Grundskole”. Hvis der er mere end to klasser, lægges de estimerede sandsynligheder sammen, så intervallerne danner udgangspunkt for, hvilken klasse, der tildeles ved Monte Carlo simulation. I eksemplet udtrækkes værdien 0.62 og individet tildeles klassen ”Erhvervsfaglig uddannelse”.

Jo større antal personer, der udsættes for Monte Carlo simulationen for de givne karakteristika, der er brugt til at estimere de pågældende sandsynligheder, jo mere vil fordelingen af personerne tilnærme sig de estimerede sandsynligheder. Eller omvendt, hvis der kun er få personer, der udsættes for en hændelse, jo større vil afvigelsen fra de estimerede sandsynligheder typisk være.
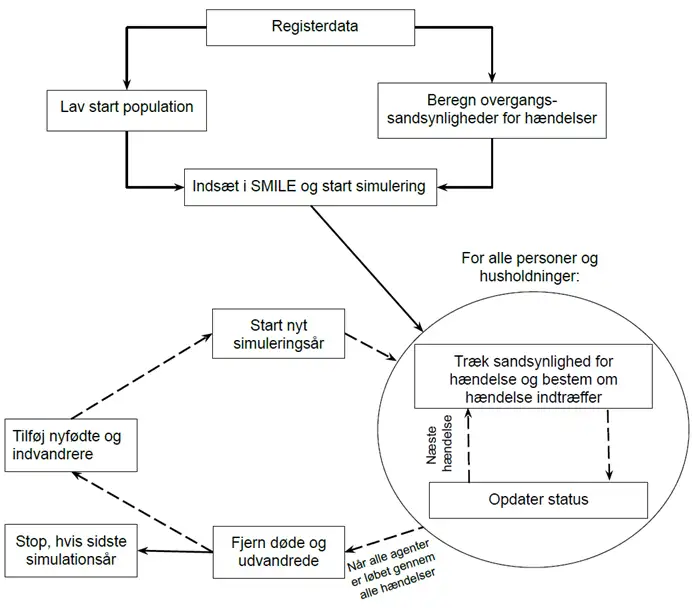
Når startpopulationen, imputationsmodeller og overgangssandsynligheder er på plads, indlæses de i SMILE, som er programmeret i C#. Hvert individ og familie fremskrives nu år for år et år ad gangen. Simplificeret, så trækkes der en sandsynlighed for, om en givet hændelse indtræffer, personens status opdateres og den nye information gemmes i en database. Dette gøres for alle personer for alle (relevante) hændelser. Nyfødte og indvandrere tilføjes, mens udvandrede og døde fjernes. Et nyt år startes og sådan køres simulationen rundt indtil den ønskede periode for analysen er simuleret. Flowet er vist i figuren nedenfor.